
Pengujian Performa
Contents
ASUS telah dikenal oleh umum sebagai produsen berbagai produk konsumer berkualitas seperti gadget, laptop, maupun komponen PC. Mengikuti perkembangan permintaan pasar akan komputasi kelas enterprise, saat ini ASUS mulai menapaki pasar server dengan lebih serius. Kali ini EFISON kedatangan server ASUS ESC4000A-E10 yang ditenagai CPU AMD EPYC Rome dengan arsitektur AMD Zen 2 dan GPU NVIDIA dengan arsitektur NVIDIA Turing.

Spesifikasi
| Tipe | Model/Spesifikasi |
|---|---|
| Processor / System Bus | 1 x Socket SP3 (LGA 4094) AMD EPYC™ 7002 Series |
| Memory | Total Slots : 8 (8-channel) Capacity : Maximum up to 2048GB RDIMM Memory Type : DDR4 3200 RDIMM DDR4 3200 LRDIMM DDR4 3200 LR-DIMM 3DS Memory Size : 256GB, 128GB, 64GB, 32GB, 16GB * Refer to support page for more information |
| Expansion Slots | Rear: – 4 x PCIe x16 slots (Gen4 x16 link, FH,FL) for dual-slot GPU cards or 8 x PCIe x16 slots (Gen4 x8 link, FH,FL) for single-slot GPU cards – 2 x PCIe x16 slots (Gen4 x16 link, LP,HL) Front: – SKU-2 (by request) – SKU-3 (by request) |
| Storage | SATA Controller : CPU Integrated 1 x M.2 connector(2242/2260/2280/22110) PCIe mode (PCIe Gen4 x4 link 22110/2280/2260) Optional kits Controller : ASUS PIKE II 3008-8i 8-port SAS 12G RAID card ASUS PIKE II 3108-8i 8-port SAS 12G HW RAID card |
| Drive Bays | 8 x 3.5″ or 2.5″ Hot-swap Storage Bays (Backplane Supports 4 x SATA/SAS + 4 x SATA/SAS/NVMe Devices) *default setting supports 2 x NVMe devices. |
| Networking | 1 x Dual Port Intel I350-AM2 Gigabit LAN controller + 1 x Mgmt LAN |
| Graphic |
Aspeed AST2500 with 64MB VRAM
|
| Front I/O Ports | 1 x Q-code/port-80 LED 4 x USB 3.2 Gen1 ports |
| Rear I/O Ports | 2 x USB 3.2 Gen1 port 1 x VGA port 1 x Management port (RJ45) 2 x Gigabit LAN ports (RJ45) |
| Switch/LED | Rear Switch/LED: 1 x Power switch/LED 1 x Location LED 1 x Message LED 1 x HDD Access LED Front Switch/LED: |
| OS Support | Please find the latest OS support from https://www.asus.com/event/Server/OS_support_list/OS.html |
| Management Solution | ASUS Control Center On-Board ASMB9-iKVM for KVM-over-IP |
| Regulatory Compliance | BSMI, CE, RCM, FCC(Class A) |
| Dimensions | 800mm x 440mm x 88.9mm (2U) 31.50″ x 17.22″ x 3.5″ |
| Form Factor | 2U |
| Power Supply | 1+1 Redundant 1600W 80 PLUS Platinum Power Supply Rating: 100-127Vac/200-240Vac,12.9A/9.5A,50-60Hz 1+1 Redundant 2200W 80 PLUS Platinum Power Supply |
| Environment | Operation temperature: 10℃ ~ 35℃ / Non operation temperature: -40℃ ~ 70℃ Non operation humidity: 20% ~ 90% ( Non condensing) |
| Note |
*Users need to remove Slimline cables from the PCIe riser board, and re-connect the cables to the backplane for total 4 x NVMe devices.
|
CPU yang datang ke lab EFISON untuk pengujian ASUS ESC4000A-E10 adalah AMD EPYC 7502P. EPYC 7502P memiliki 32 core dengan SMT yang menjadikannya 64 thread, boost clock hingga 3.35 GHz, dan L3 cache sebesar 128 MB. Dari sisi dukungan ia mendukung memori DDR4 ECC 8-channel dan PCIe 4.0 hingga 128-lanes. CPU ini merupakan salah satu dari jajaran CPU AMD EPYC Rome yang menggunakan mikroarsitektur Zen 2 dengan fabrikasi 7 nm TSMC.

Dari sisi GPU, EFISON juga diberi kesempatan untuk mencoba sebuah Nvidia Tesla T4. GPU ini menggunakan mikroarsitektur Turing dengan fabrikasi 12 nm. Tesla T4 menggunakan chip TU104 dengan 40 SM dan 2560 CUDA core. Ia memiliki ukuran single slot sehingga dapat dengan mudah dipasang di rack server 1U maupun 2U. Dari segi konsumsi daya ia hanya menggunakan daya dari slot PCIe yang tidak sampai 75 W. GPU ini dapat dipasang hingga 8 buah di server ASUS ESC4000A-E10 melalui slot PCIe di sebelah kanan dan kiri unit server.


ASUS ESC4000A-E10 mendukung hingga 8 buah 3.5″/2.5″ drive bay dengan konfigurasi maksimum 4 SATA/SAS + 4 SATA/SAS/NVMe. Pengguna juga dapat menambahkan RAID card PCIe sendiri di slot PCIe depan yang sudah disediakan.

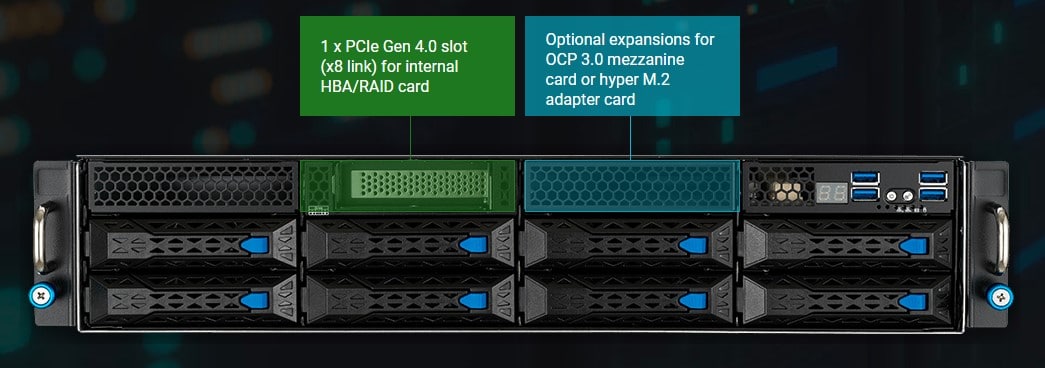
ASUS menyematkan server 2U ini dengan berbagai fitur untuk optimasi performa maupun fitur enterprise.
Performance Tuning
Pengguna dapat menyesuaikan pengaturan optimasi performa menyesuaikan workload secara otomatis berdasarkan profile dari ASUS. Untuk mengakses fitur Performance Tuning ini, pengguna cukup masuk ke System Setup (BIOS) dengan menekan DEL saat startup, lalu masuk ke tab menu Performance Tuning.
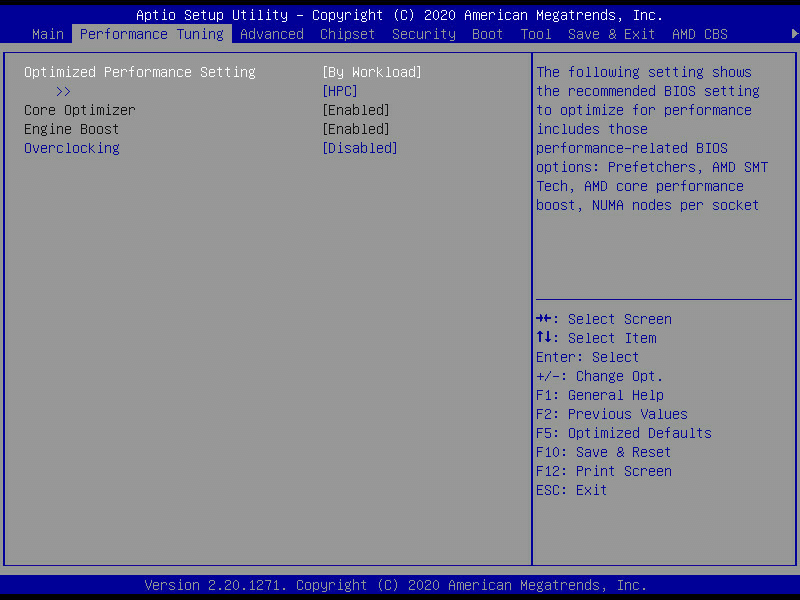
Pengguna dapat memilih setelan optimasi berdasarkan workload maupun benchmark.
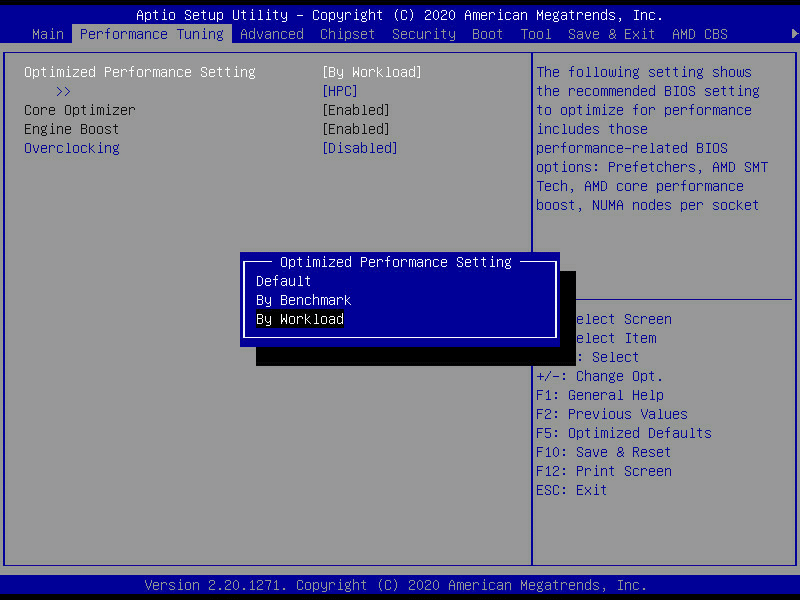
Pada pengujian kali ini EFISON menggunakan opsi By Workload: HPC.
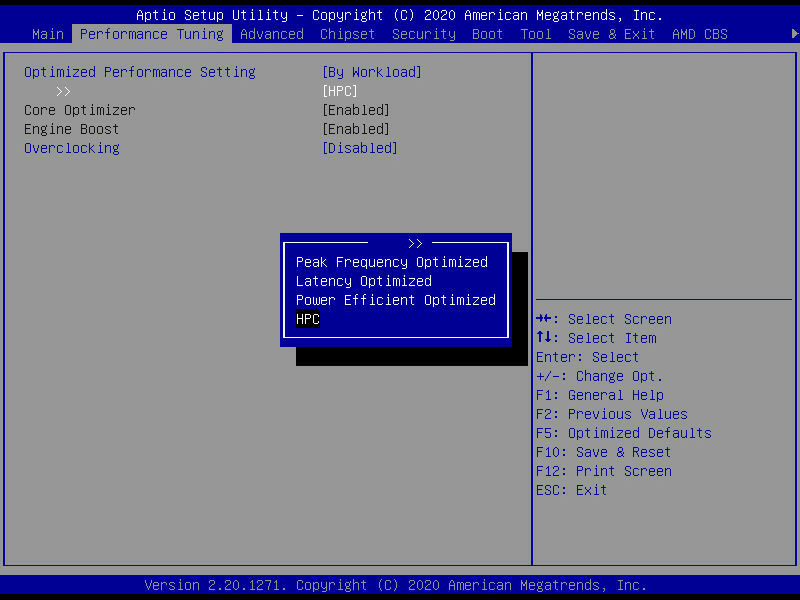
Pengguna juga dapat melakukan overclocking otomatis dengan enable menu overclocking di bawah. Pada pengujian kali ini, EFISON menggunakan setelan Overclocking: Disabled.
BMC WebUI
Pengguna dapat melakukan monitoring kondisi hardware, update firmware, update BIOS, maupun remote control melalui WebUI.
Pengujian performa dilakukan dengan berbagai software sintetis maupun software saintifik. Berikut adalah konfigurasi hardware dan software yang digunakan.
| Tipe | Model/spesifikasi |
|---|---|
| CPU | 1 * AMD EPYC 7502P 32c/64t 180W |
| GPU | 1 * Nvidia Tesla T4 |
| RAM | 128 GB DDR4-3200 ECC 8-channel |
| Storage | 120 GB Intel SSD DC S3500 Series |
| OS | CentOS 7.8 |
| Kernel | 5.9.1-1.el7.elrepo.x86_64 |
Berikut adalah software yang digunakan dalam pengujian. Seluruh software di-build dari source dengan berbagai optimasi compiler dan library untuk memaksimalkan performa dari software tersebut.
| Software | Versi | Compiler/Library | Optimasi |
|---|---|---|---|
| High-Performance LINPACK | 2.3 | Compiler: GNU 9.3.0 MPI: BLAS: |
Compiler: -march=znver2 BLAS: |
| High-Performance Conjugate Gradient | 3.1 | Compiler: GNU 9.3.0 MPI: (Khusus HPCG GPU, menggunakan binary dengan dukungan CUDA 11 dari web HPCG) |
Compiler: -march=znver2 |
| GROMACS | 2020.3 | Compiler: GNU 9.3.0 MPI: BLAS: LAPACK: CUDA: |
Compiler: -march=znver2 CUDA: |
| NAMD | 2.14 | Compiler: GNU 9.3.0 FFTW: CUDA: |
Compiler: -march=znver2 BLAS: CUDA: |
High-Performance LINPACK (HPL)
HPL adalah software yang menyelesaikan sistem linier padat acak dalam aritmatik double precision (64-bit) pada komputer dengan memori terdistribusi. HPL merupakan standar benchmark high-performance computing (HPC) dan superkomputer di dunia. Benchmark HPL juga digunakan sebagai tolok ukur performa 500 superkomputer tercepat di dunia yang dirangkum pada laman Top500.
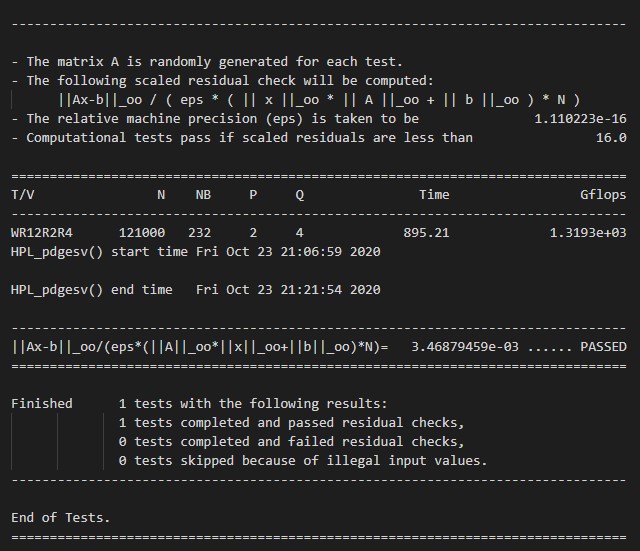
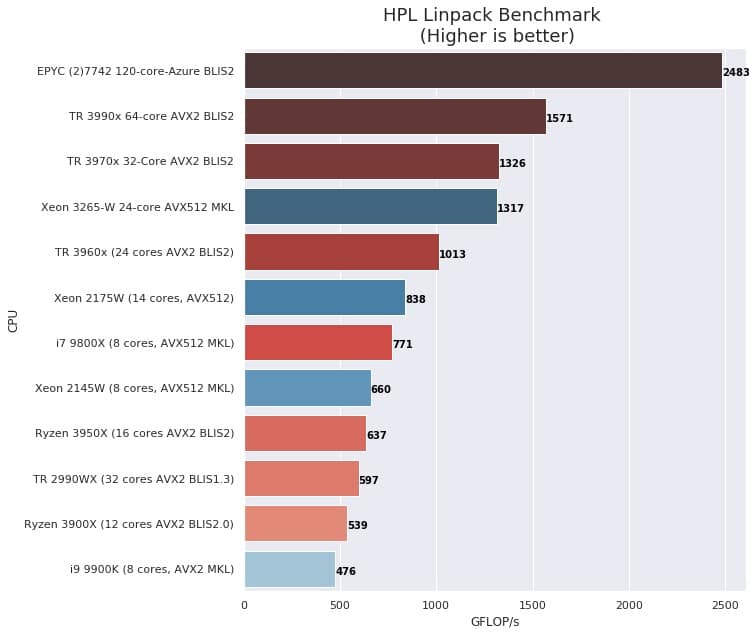
Hasil pengujian HPL menghasilkan skor 1319.3 GFLOPS. Hasil yang dicatatkan oleh EPYC 7502P ini termasuk kencang apabila dibandingkan dengan berbagai CPU kelas workstation maupun enterprise. Sebagai perbandingan, berikut adalah hasil benchmark HPL oleh Dr. Donald Kinghorn dari Puget Systems terhadap berbagai CPU.
High-Performance Conjugate Gradient (HPCG)
HPCG adalah software benchmark yang melakukan iterasi gradien konjugasi prakondisi multigrid menggunakan nilai floating-point double precision (64-bit). HPCG umum digunakan sebagai suplemen benchmark HPL dan menjadi ukuran efisiensi performa superkomputer dengan perhitungan (hasil HPCG dalam FLOPS/hasil HPL dalam FLOPS).
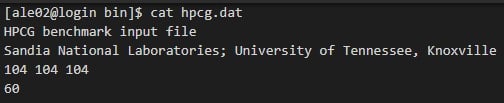
Pada pengujian HPCG, digunakan konfigurasi problem size 104 104 104 agar HPCG juga bekerja menguji memori dan tidak hanya berjalan di cache prosesor.
HPCG CPU
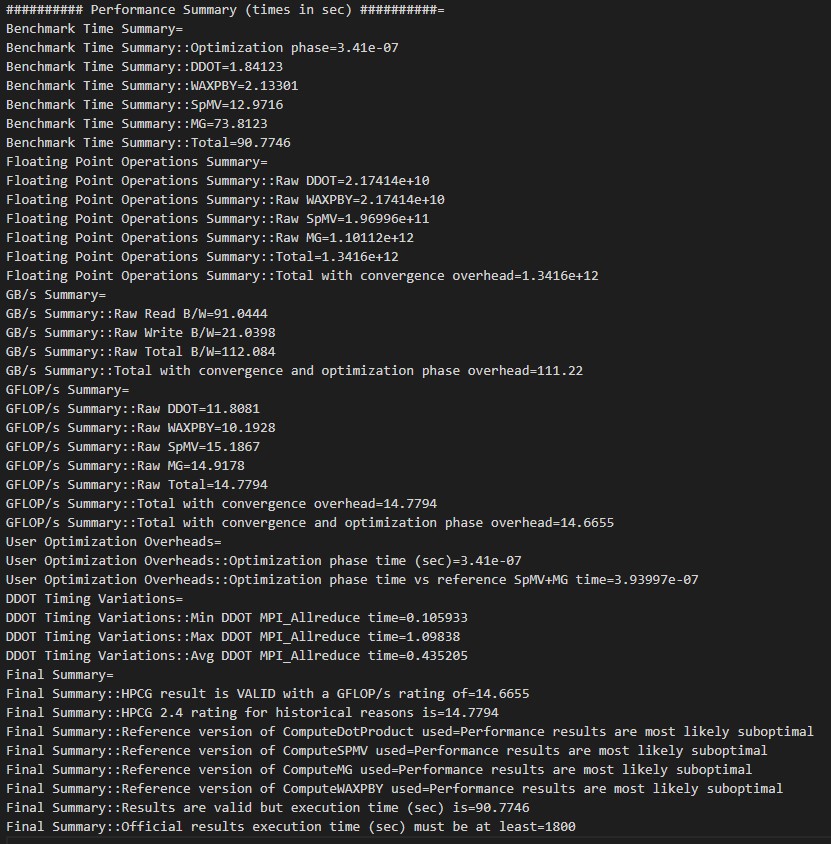
Pengujian HPCG CPU menghasilkan skor dari AMD EPYC 7502P sebesar 14.6655 GFLOPS. Sebagai pembanding, berikut adalah data hasil benchmark HPCG CPU dari Puget Systems.
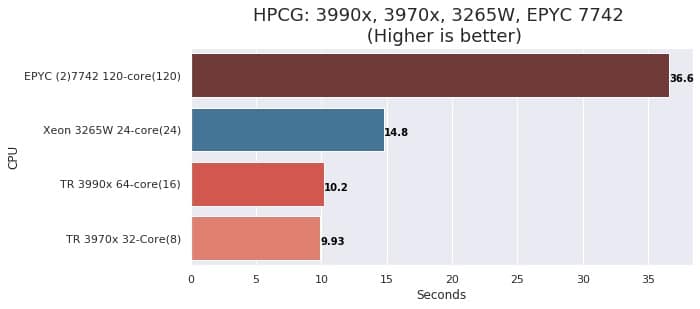
Skor EPYC 7502P relatif lebih cepat dibanding Threadripper berkat keunggulan 8-channel memori dibanding Threadripper yang hanya 4-channel.
HPCG GPU
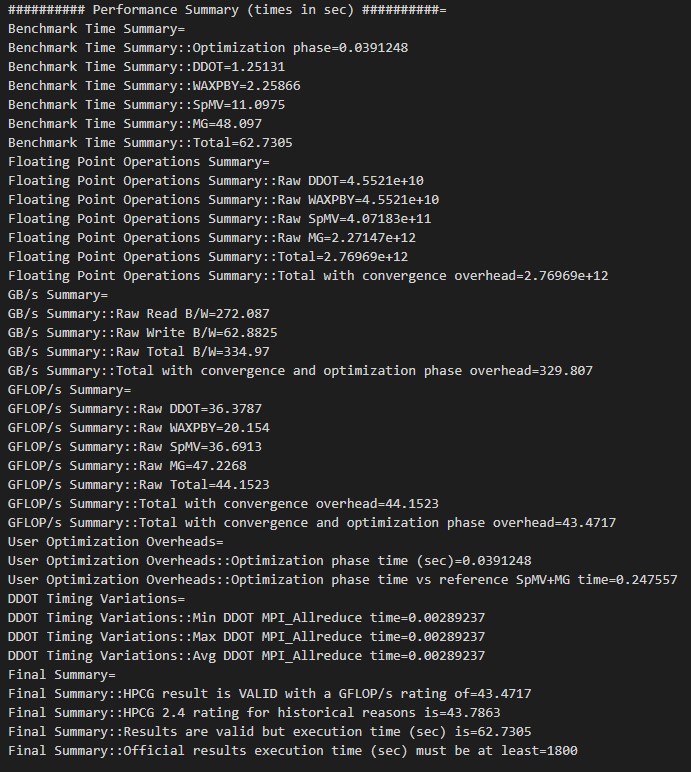
Pengujian HPCG GPU menghasilkan skor dari Nvidia Tesla T4 sebesar 43.4717 GFLOPS. Sebagai pembanding berikut adalah data hasil benchmark HPCG GPU dari Puget Systems.
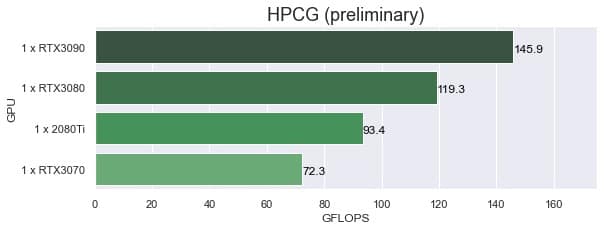
Skor Nvidia Tesla T4 memang jauh lebih rendah apabila dibandingkan dengan GPU kelas konsumer high-end, namun perlu diingat pula Nvidia Tesla T4 memiliki ukuran yang lebih ringkas (hanya 1 slot PCIe) serta konsumsi daya maksimum yang lebih rendah. Hal ini akan sangat membantu apabila pengguna ingin memasang konfigurasi banyak GPU pada server ASUS ESC4000A-E10 ini.
GROMACS
GROMACS adalah software saintifik untuk melakukan perhitungan dinamika molekuler seperti mensimulasikan persamaan gerak Newton pada sistem dengan jutaan partikel. Ia didesain untuk molekul biokimia seperti protein, lipid, dan asam nukleat yang memiliki banyak interaksi ikatan kompleks.
Pengujian dilakukan menggunakan file input RNAse dodecahedron PME.
GROMACS CPU
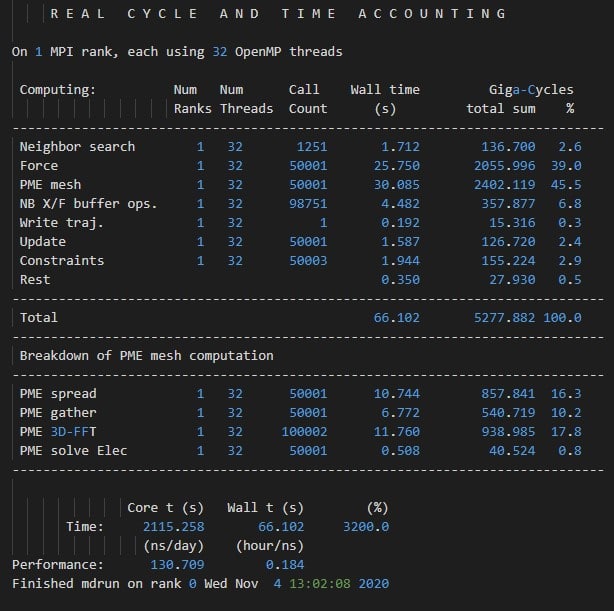
Pada pengujian GROMACS RNAse menggunakan EPYC 7502P, didapatkan hasil hingga 130.709 ns/day. Task hanya menggunakan hingga 32 core untuk mempopulasi jumlah core fisik. Penggunaan hanya core fisik tanpa SMT menghasilkan performa yang lebih cepat dibandingkan dengan mempopulasi seluruh thread.
GROMACS CPU + GPU
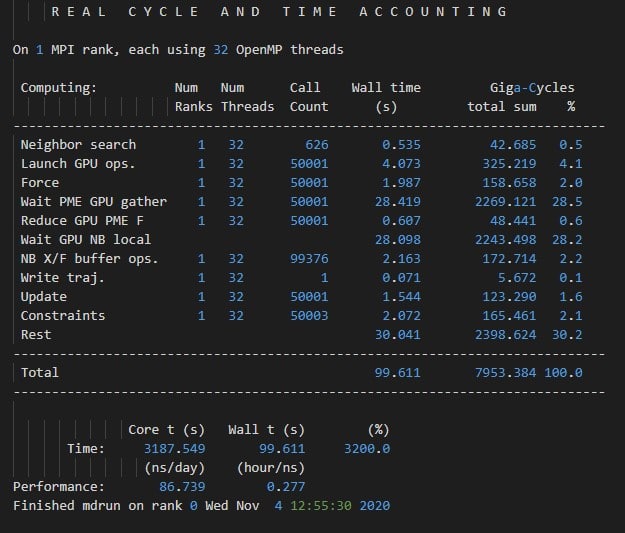
Penggunaan GPU Nvidia Tesla T4 pada pengujian GROMACS RNAse dodecahedron PME menghasilkan akselerasi negatif. Hal ini dikarenakan jumlah GPU yang digunakan terlalu sedikit sehingga off-load tugas dari CPU ke GPU justru lebih tidak efisien. Terlihat bahwa wall time boros di Wait PME GPU gather dan Wait GPU NB local. Hasil pengujian mencatatkan hanya 86.739 ns/day, lebih kecil dibanding hanya menggunakan CPU.
NAMD
NAMD merupakan software saintifik dinamika molekuler paralel yang didesain untuk melakukan simulasi dari sistem biomolekuler besar. Software ini mampu scaling hingga ratusan core untuk simulasi biasa dan lebih dari 500.000 core untuk simulasi besar.
Pengujian dilakukan menggunakan file input ApoA1. Hasil ditunjukkan dalam bentuk skalabilitas terhadap jumlah core.
NAMD CPU
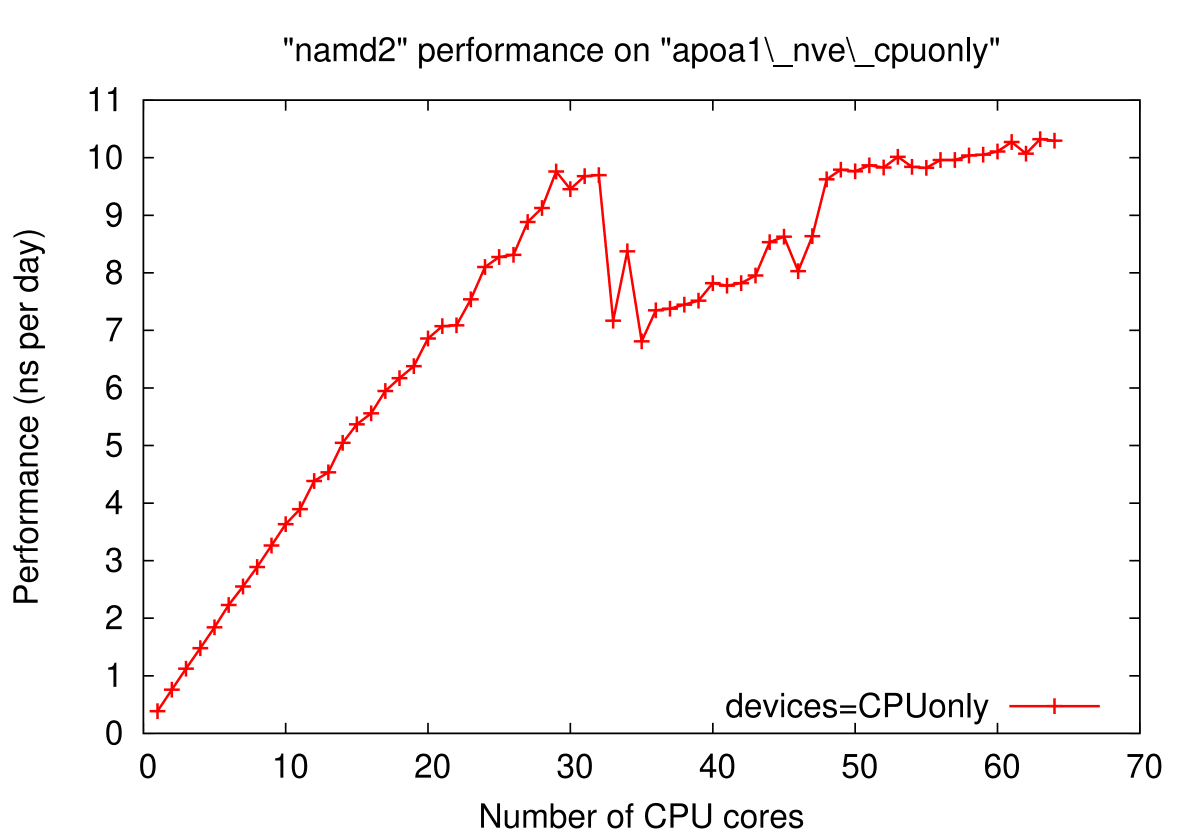
Komputasi NAMD menggunakan AMD EPYC 7502P tanpa dibantu Nvidia Tesla T4 menghasilkan performa yang scaling hingga jumlah task NAMD sama dengan jumlah core fisik (32 core). Pada penggunaan 32 core, 7502P menghasilkan 9.69558 ns/day sedangkan penggunaan maksimum 64 task menghasilkan 10.2963 ns/day.
NAMD CPU + GPU
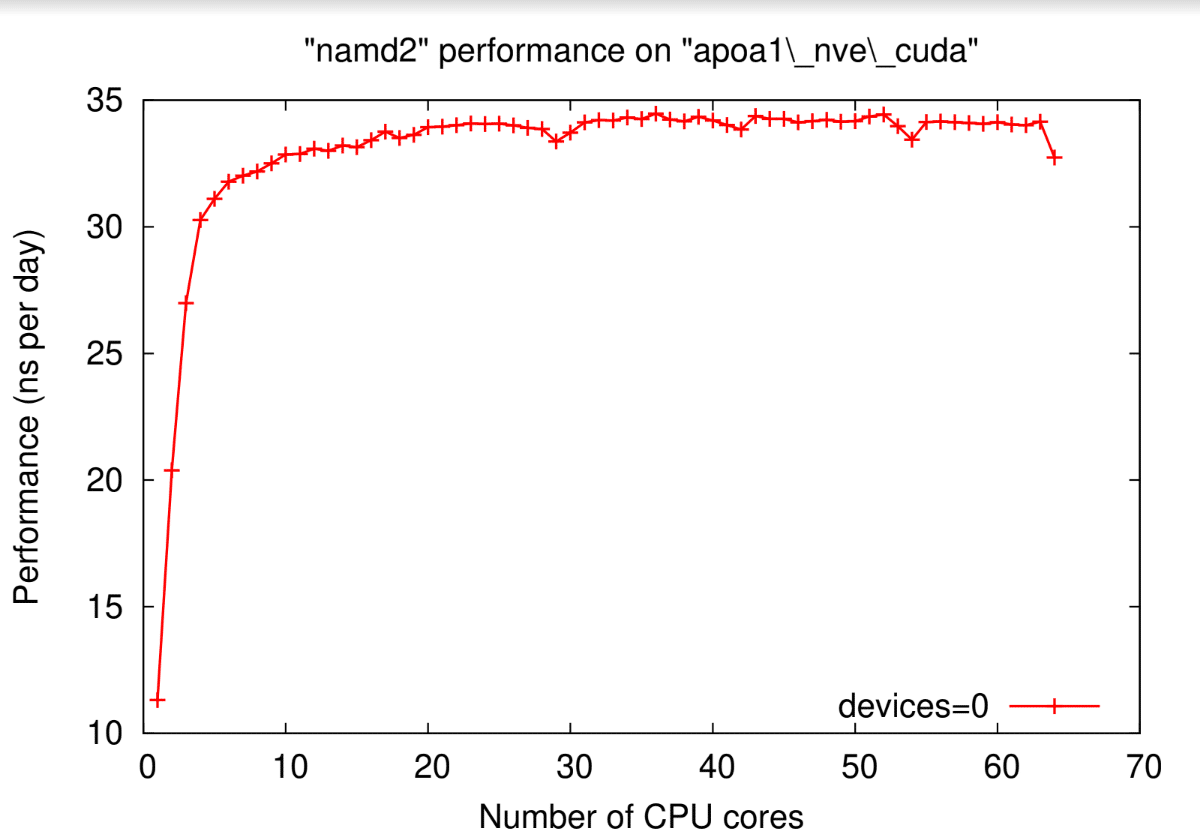
Komputasi NAMD menggunakan EPYC 7502P dengan dibantu Nvidia Tesla T4 menghasilkan performa komputasi yang jauh lebih baik, hingga lebih dari 32 ns/day.
Server ASUS ESC4000A-E10 ini merupakan server 2U menarik dengan berbagai fitur yang layak untuk digunakan dalam ekosistem HPC. Fitur optimasi performa menggunakan profile workload maupun software di BIOS, dukungan CPU AMD EPYC Rome dengan memori 8-channel DDR4-3200, serta slot PCIe 4.0 hingga 8 GPU menjadikan server ini sangat layak untuk dijadikan pilihan komputasi berat seperti saintifik, machine learning, AI inference, hingga workstation.
Terkait ketersediaan, ASUS menjanjikan server ini hadir di pasar Indonesia antara Q4 2020 atau Q1 2021. Mengenai prosesor AMD EPYC Milan (7003-series) yang akan datang kemungkinan akan didukung, tentunya hal ini menunggu pula informasi rilis dari AMD maupun ASUS.